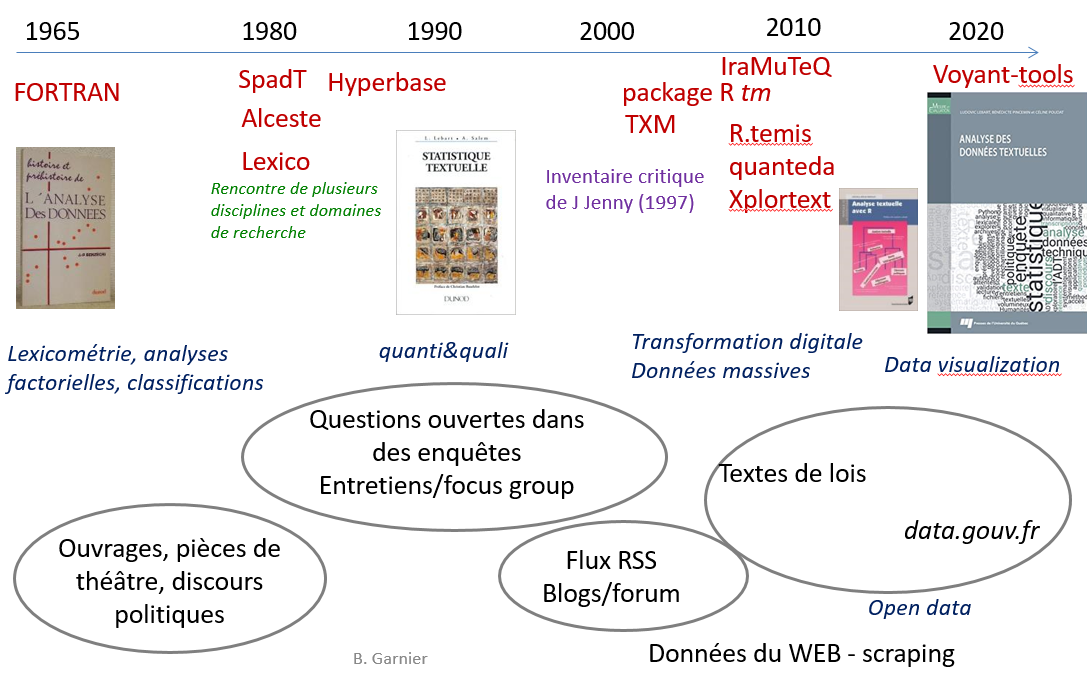
Statistique textuelle et data Science
Enjeux de la statistique (textuelle)
- Explorer : faire naître des idées, détecter des similitudes, des différences, des anomalies, ….
- Résumer les données à l’aide d’ indicateurs, de profils
- Présenter des résultats …

mais aussi :
- Structurer : le corpus en base de données et le nettoyer
Place de la Statistique textuelle
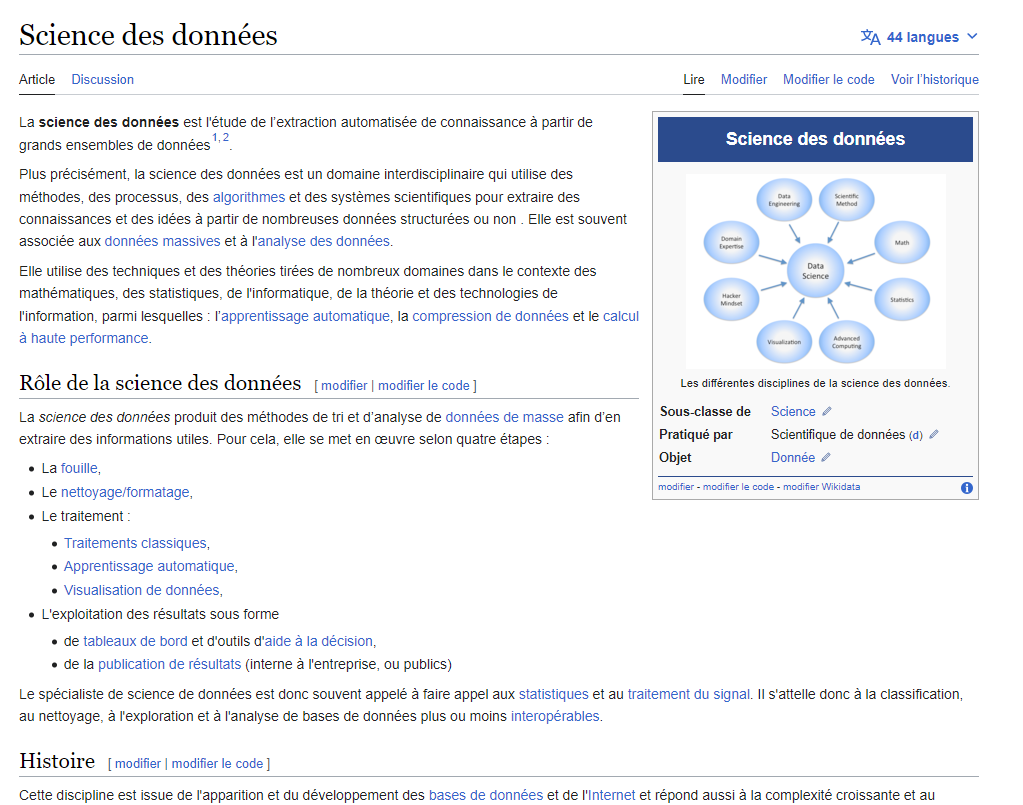
et si on allait voir ce que dit Wikipedia sur la Science des données
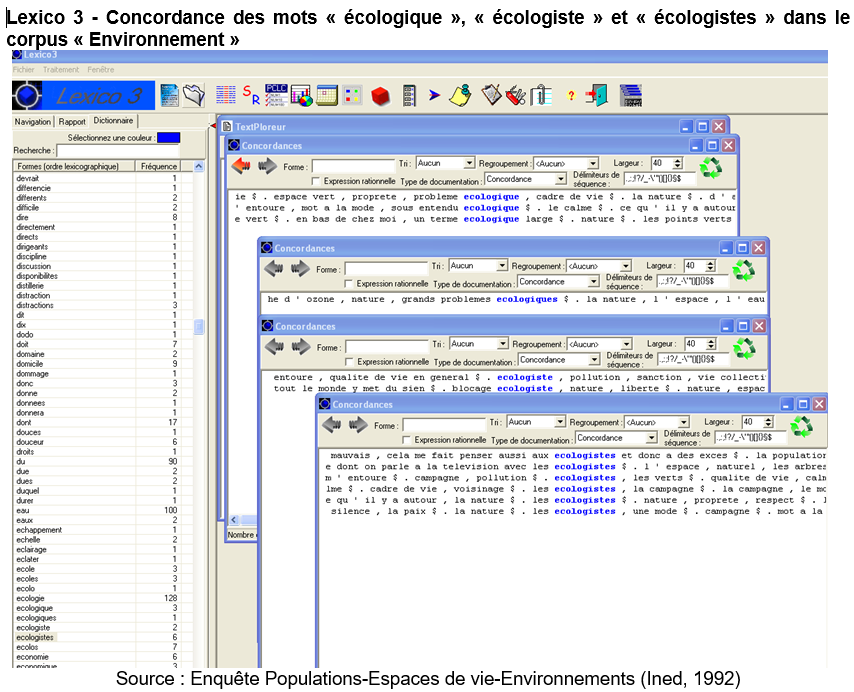
Afficher des concordances
Le concordancier : indispensable tout au long d’une analyse de texte, quel qu’il soit :
L’Analyse des Données

Usage croissant
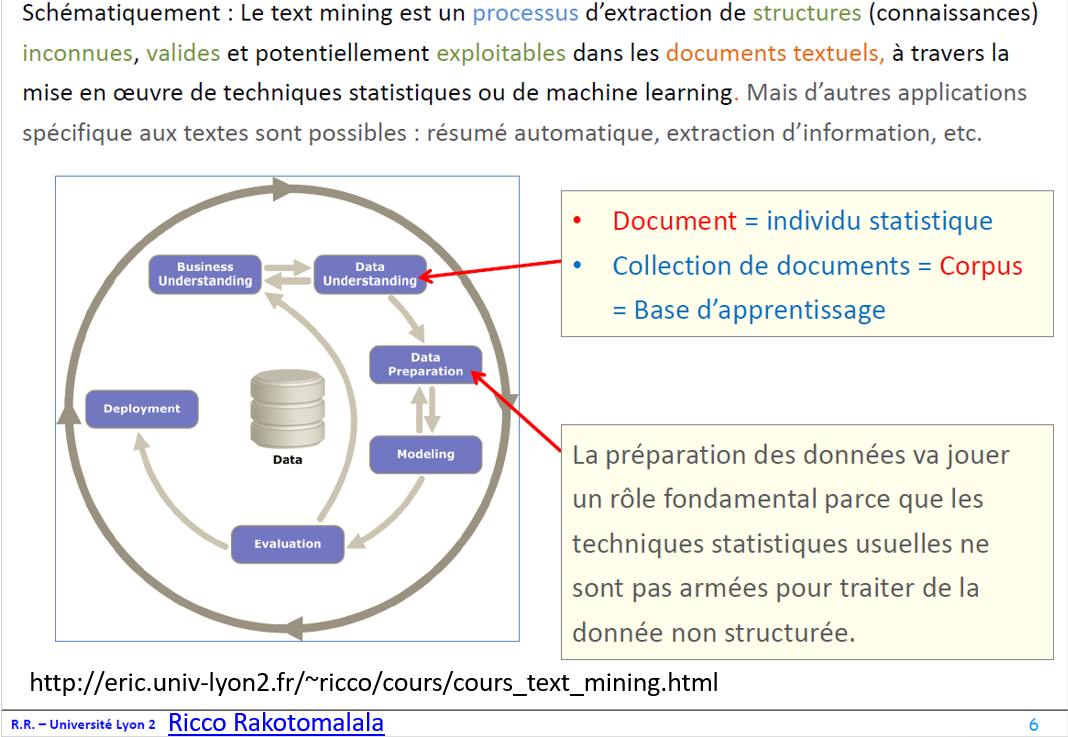
Text Mining
Topic Model
Modèle probabiliste permettant de déterminer des champs lexicaux dans un document (apprentissage automatique - traitement automatique du langage naturel (TLN))
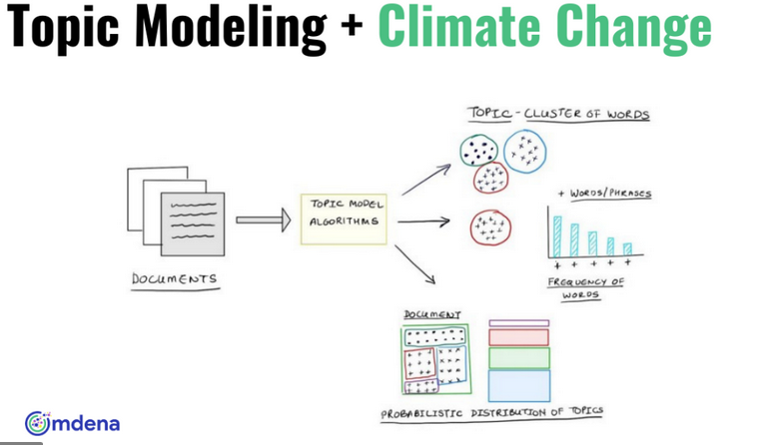
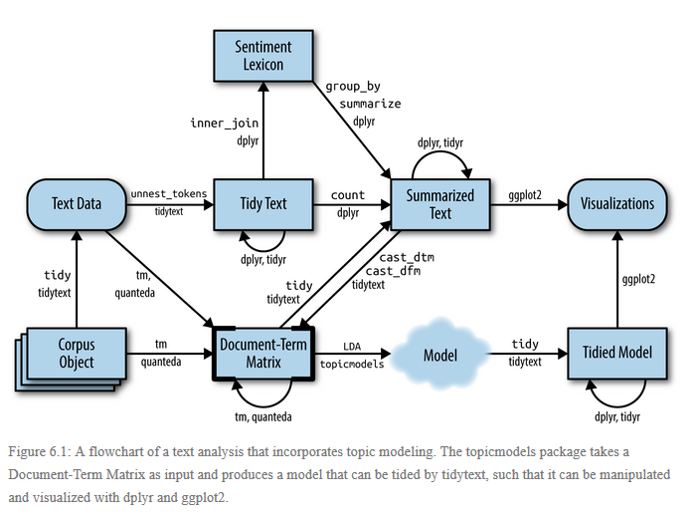
Chaîne de traitement de textes
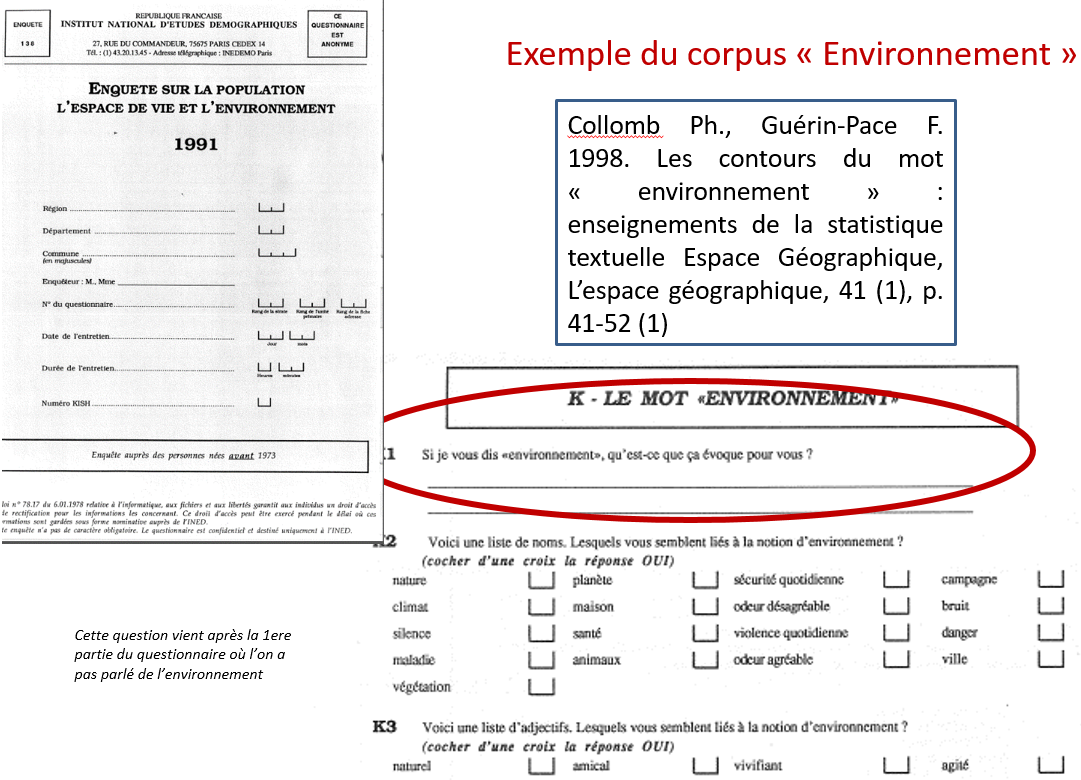
Exemple de question ouverte dans un questionnaire
Le tableau lexical entier (TLE)

Tableaux dits hyper-creux. Présence/absence de mots dans les textes (Valeur positive ou nulle). L’ordre des mots n’est pas pris en compte (sacs de mots)
Lecture du lexique
- Les mots vont constituer le dictionnaire ou lexique associé au corpus et deviennent des descripteurs : les termes
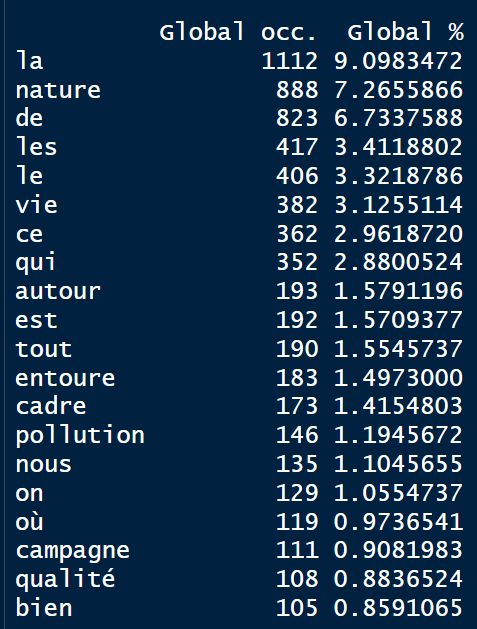
Lecture des mots par ordre de fréquence (occurrence), ordre alphabétique.
Analyse des correspondances sur le tableau lexical entier
Les plans factoriels permettent de visualiser des proximités de mots, des oppositions et ainsi de repérer des champs lexicaux
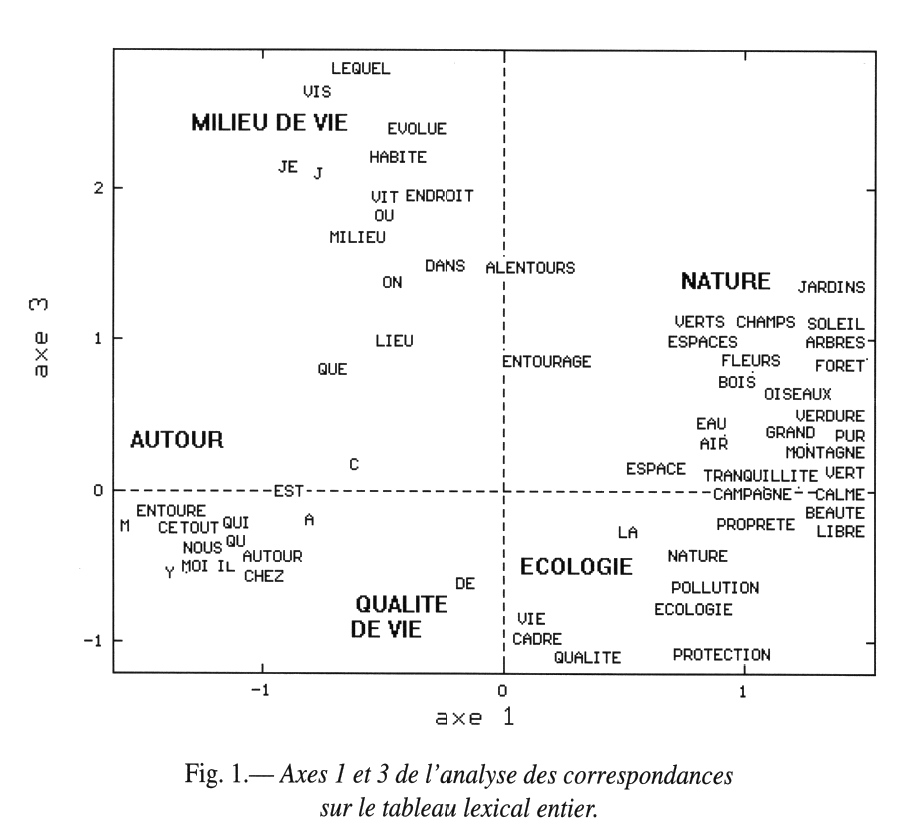
(Enquête Populations, Espaces de vie, Environnements, Ined 1992)
Deux mots sont d’autant plus proches que leurs contextes d’utilisation se ressemblent et d’autant plus éloignés qu’ils seront rarement utilisés ensemble
Classification sur Tableau Lexical
Obtenir un classement des unités de textes en fonction de la ressemblance ou de la dissemblance des mots dans ces textes et d’ordonner les textes en cernant les homologies et les oppositions (Rouré, Reinert, 1993)
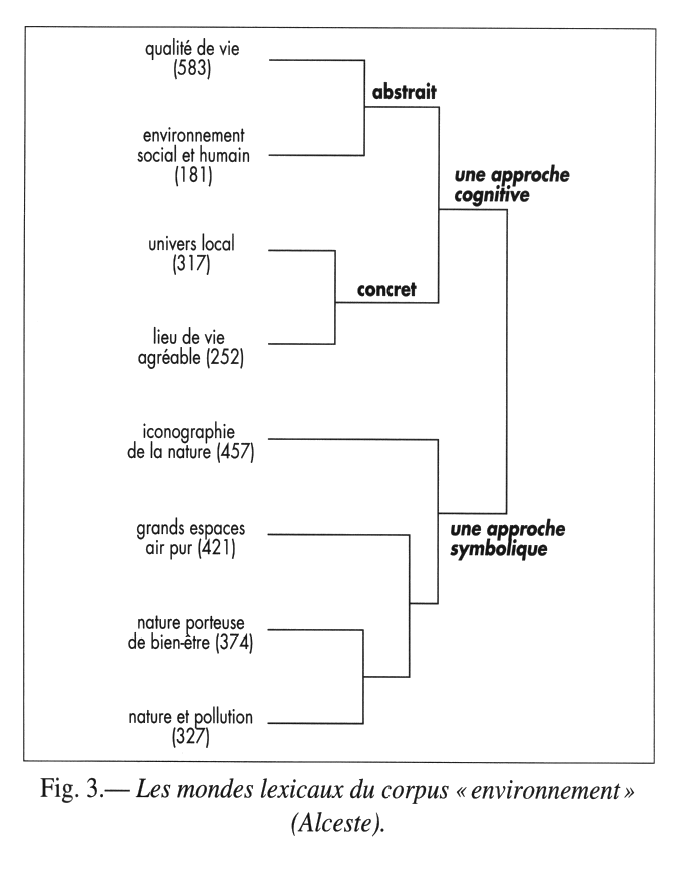
Méthode Alceste ( Reinert, 1983), aujourd’hui implantée dans le package Rainette (J. Barnier)
Les spécificités
Utilisation d’un test statistique pour dire si l’écart entre la fréquence relative d’une forme dans une partition (par modalité) et la fréquence globale calculée sur l’ensemble des réponses est significatif ou non
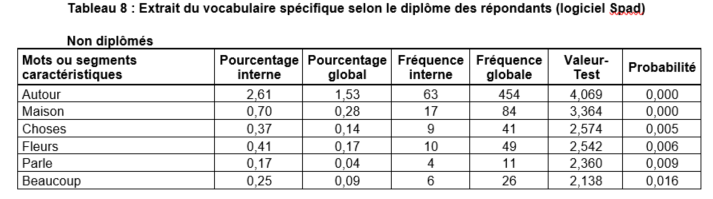
(Enquête Populations, Espaces de vie, Environnements, Ined 1992)
Les mots ou textes caractéristiques de ces partitions sont restitués selon leur degré de spécificité
Le tableau lexical agrégé (TLA)
Tableau de contingence qui croise les mots du lexique et les modalités des métadonnées.

(Populations, Espaces de vie, Environnements, Ined, 1992)
Analyse des correspondances sur un Tableau Lexical Agrégé
Le plan factoriel permet d’observer la position réciproque des “mots” et des métadonnées et de faire émerger des champs lexicaux propres à des sous-populations

(Enquête Populations, Espaces de vie, Environnements, Ined 1992)
- 2 mots proches = proximité des individus - profils lignes
- 2 caractéristiques proches = univers lexicaux proches - profils colonnes
Les outils
Liste non exhaustive
